“超级VC”,又回来了。

文|猎云网 王非
“我们也一样在埋头研发,但是并不急于早早做完,把半成品拿出来展示。”
在腾讯2023股东大会上,马化腾针对大模型“低调、憋大招”这一问题,作出了上述回答。
掌舵者“不急”,腾讯上下自然“低调”。自研“混元大模型”之外,对外投资亦是如此。
就在刚刚过去的周五,一天之内,腾讯接连被爆投资两家大模型创企。“首次投资”来源于市场消息,第二次则来源于白纸黑字的工商变更。
伴随腾讯大手笔投资,前者据传已成为“独角兽”,后者也相差不远。
依然是熟悉的感觉,腾讯这个“超级VC”,又回来了!
大模型热潮之下,被冠以“腾讯首次投资”的创企,名为MiniMax。
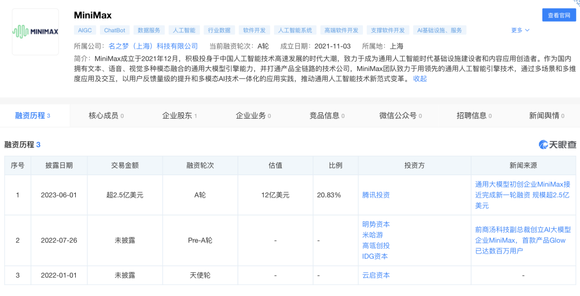
6月1日,据路透社报道,国内通用大模型初创企业MiniMax完成了超2.5亿美元新一轮融资,目前公司估值超12亿美元。在本轮融资中,有腾讯有关联的实体参与,参投资金或为4000万美元。
此前,MiniMax已完成两轮融资,投资方包括米哈游、IDG资本、高瓴创投、云启资本、明势资本等。云启资本曾在4月份发文确认,该机构于2021年投资MiniMax,是天使轮中唯一的早期投资机构。
来源:天眼查
公开资料显示,MiniMax隶属于名之梦(上海)科技有限公司,该公司注册成立于2021年11月。MiniMax联合创始人为前商汤科技副总裁、通用智能技术负责人闫俊杰,也曾担任商汤研究院副院长。
MiniMax法定代表人、技术合伙人杨斌于2014年在中科院自动化所第一次参与深度学习相关的项目,2016年前往加拿大多伦多大学攻读博士学位。在海外留学期间,他先后作为创始团队成员在Uber ATG研究院、自动驾驶初创公司Waabi等团队供职,拥有多年研发经验,对基于数据驱动的端到端系统问题颇有研究。
今年2月16日,MiniMax在北京举办的小型媒体沟通会上曾透露,团队人数已过百,公司核心技术研发成员均来自全球知名高校和全球顶尖科技公司,拥有世界顶尖自然语言处理、语音、计算机视觉、计算机图形学等工业界和学术界经验,1/3的团队成员拥有世界顶尖技术实验室的博士学位。
据介绍,MiniMax直接从底层的基础模型做起,自研了三个foundation model(基础模型)——文本到视觉(text to visual)、 文本到语音(text to audio ),文本到文本( text to text)。
杨斌表示,MiniMax可能是国内第一家同时拥有三个模态大模型能力的创业公司。“只要做好这三个模态的基础大模型,就能提供非常好的内容生成能力。”
而在三个基础模型之上有一个计算推理平台,将三个基础大模型的能力以一种低成本、高鲁棒性的方式释放给用户。
目前,基于该推理平台MiniMax在去年11月推出了第一款to C的用户产品Glow,是一款能够让你与AI(人工智能)技术创造的“智能体”实时交流、沉浸互动并建立情感羁绊的应用。上线四个月后,其注册用户数量已达近500万。

来源:官网截图
Glow官网显示,该产品隶属于北京稀宇科技有限公司,注册成立于2022年9月,法定代表人为周彧聪。作为MiniMax核心成员之一,周彧聪也被证实是商汤科技早期员工之一,曾经在商汤科技研究院带领算法团队。
杨斌还表示,MiniMax的初心是实现通用人工智能,而这必须要靠一个开放的生态。所以从今年开始,MiniMax会逐步开放API,让更多的个人用户和企业用户基于多种模态的大模型构建自己的应用。
于是在3月份,MiniMax就推出了面向企业用户的API开放平台,支持文本和语音模型的服务调用。
4月18日,金山办公发布生成式AI应用WPS AI,接入的正是国内合作伙伴MiniMax的自研大模型。基于MiniMax三个模态的基础大模型,WPS AI目前已提供文档的起草、改写、总结、润色、翻译、续写等功能,并将在人机交互问答方向持续优化。
除WPS外,MiniMax还与国内游戏、社交网络等多个行业内的头部公司达成合作,国产自研大模型正在迅速成为生活中的基础设施,为人们的生活和工作带来便捷和高效。
值得一提的是,在大模型对战平台SuperCLUE琅琊榜首发排行榜上,MiniMax模型以1188分登顶国服,全球位列第二。
位列第一的是Anthropic公司开发的Claude,紧随MiniMax其后的是1171分的GPT3.5。
这是国内大模型首次在公开测评中超过GPT3.5。
天眼查App显示,5月31日,北京深言科技有限责任公司发生工商变更,股东新增腾讯旗下广西腾讯创业投资有限公司、好未来旗下公司欣欣相融教育科技 (北京)有限公司等,同时,注册资本由约131.6万增至约183.5万元。
所以,从时间维度,以及工商变更的确定性上,深言科技才是腾讯“首次投资”的大模型创企。
有意思的是,此次腾讯好未来入股深言科技,颇有“捡漏”的意味。
作为最早一批入局大模型的互联网大佬,王慧文在招兵买马上速度惊人。“带资进组”的他,自然可以用“买买买”来换取时间。
潜在的收购目标,至少有三家:一流科技、面壁智能、深言科技。最终,王慧文成功并购了一流科技,对另外两家清华NLP校友公司“很感兴趣”的消息,也在市场上流传一时。
据称,王慧文确实与面壁智能团队有过接触和交流。经综合考虑,这家公司还是决定独立发展,并在后续获得了知乎投资。
此前,深言科技已“低调”完成两轮融资,并未官宣,投资方包括奇绩创坛、英诺天使基金、红杉中国等。据传,该公司完成第二轮融资时,估值已达1亿美元。
可能是因为发展势头迅猛,王慧文为光年之外挑选潜在并购对象时,才会考虑过深言科技。也或许是后者估值已然较高,才让两者“遗憾错过”,最终“成全”了腾讯和好未来。
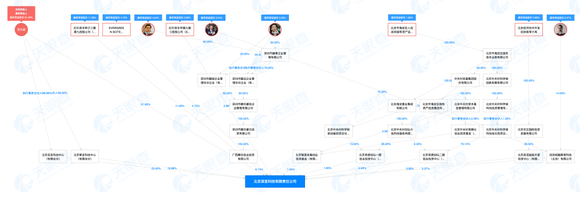
股权结构图显示,深言科技创始人兼CEO岂凡超作为实际控制人,最终受益股份达61.28%,马化腾最终受益股份为4.04%,张邦鑫则为2.54%。
来源:天眼查
深言科技创始人兼CEO岂凡超,清华大学电子工程系2013级本科,计算机科学与技术系2017级博士,主要研究方向为NLP,曾在EMNLP等顶会发表论文30多篇。
据岂凡超介绍,深言科技团队孵化自清华大学自然语言处理实验室(THUNLP)和北京智源人工智能研究院,由欧洲科学院院士、清华大学计算机系教授孙茂松领衔担任公司首席科学家。目前,团队已发表顶会顶刊论文数百篇,获得各类知识产权数十项。涵盖文本理解、文本生成、知识图谱等多技术方向,拥有自研可控文本生成大模型以及相关数据清洗、处理技术专利。
值得一提的是,THUNLP是国内第一个开展NLP研究的科研单位,早在上世纪70年代就已经成立。
基于此,岂凡超在第三届“清华大学国强研究院杯”双创大赛上底气十足,“我们的团队来自国内最早做NLP的研究机构,在NLP领域深耕30年,有国内最多的中文大模型训练经验。”
ChatGPT爆火后,深言科技发现了该产品的局限性:由于天然的语言差异和中英文屏障,国外的英文大模型无法较好地用于中文文本信息处理场景,存在中文领域知识掌握不足等问题。而中文大模型的研发远未成熟,实际性能相较英文大模型仍有不小差距。
深言科技希望以自研的中文超大规模预训练模型为核心构建工业级中文信息处理引擎,并研发最优秀的产品,引领中国的文本信息处理智能化革命,为中国的3亿脑力劳动者和数千万信息密集型组织重塑信息处理全流程。
在路演环节,岂凡超也公布了深言科技的部分成绩,“我们的大规模预训练模型在续写、改写、扩写、摘要4类文本生成任务和6个数据集上均超过现有其他中文模型,达到了当前最好的中文文本生成效果。”
最终,深言科技的“基于超大模型的新一代语言理解与生成平台”,斩获技术创新赛初创组一等奖。
巧合的是,正是在今年1月13日,深言科技获得上述奖项的同一天,奇绩创坛、红杉中国、零以资本完成了对该公司投资的工商变更。
自研+投资,一直被认为是企业发展的两条腿。
腾讯,也不例外。
早在2019年时,马化腾就对外表示,腾讯已建立四大AI实验室,涵盖AI从全面基础研究到多种应用开发。
2022年4月,腾讯首次对外披露旗下混元AI大模型的研发进展,该模型包含但不限于:计算机视觉、自然语言处理、多模态内容理解、文案生成、文生视频等多个方向的超大规模AI智能模型。
随后,腾讯于2022年12月推出了万亿中文NLP预训练模型HunYuan-NLP-1T(混元AI大模型),是目前国内首个低成本、可落地的NLP万亿大模型,且登顶自然语言理解任务榜单CLUE。目前,该模型已成功落地于腾讯广告、搜索、对话等内部产品并通过腾讯云服务外部客户。
在5月17日一季度财报会上,腾讯高管也回应称,混元大模型“进展很不错”。
具体来看,数据方面,一方面是来自互联网公共数据,一方面是腾讯内部数据,后者相对公共数据具有更高价值;模型序列方面,也正在增加训练量;基础设施方面,云和高性能计算集群,增加了训练模型的效率,这是腾讯的优势。
针对传闻中“腾讯针对类ChatGPT对话式产品成立‘混元助手’项目组”,腾讯也曾作出回应:相关方向上已有布局,专项研究也在有序推进。
据职场Bonus消息,这个项目组的负责人正是腾讯史上最高职级拥有者——张正友(腾讯首位17级研究员/杰出科学家)。
除了与大模型相关的直接消息,在间接层面,腾讯方面也在陆续释出动态:
3月30日,腾讯发布了全新的AI智能创作助手“腾讯智影”,推出了智影数字人、文本配音、文章转视频等AI创作工具。
其中,智影数字人能实现“形象克隆”和“声音克隆”,创作者通过上传少量图片、视频和音频素材,就能得到自己的数字人分身和定制音色,进而快速生成自己的数字人播报视频。
4月14日,腾讯云正式发布面向大模型训练的新一代HCC(High-Performance Computing Cluster)高性能计算集群。该集群采用腾讯云星星海自研服务器,搭载英伟达最新代次H800 GPU,服务器之间采用业界最高的3.2T超高互联带宽,为大模型训练、自动驾驶、科学计算等提供高性能、高带宽和低延迟的集群算力。
据腾讯介绍,实测显示,新一代集群整体性能比过去提升了3倍,是国内性能最强的大模型计算集群。
5月16日,AI绘图工具Midjourney也选择以QQ为载体,开启官方中文版内测……
对于AI的重要性,马化腾在股东大会上掷地有声,“我们最开始以为这是互联网十年不遇的机会,但是越想越觉得这是几百年不遇的、类似发明电的工业革命一样的机遇,所以我们觉得(AI)非常重要。”
所以,“对于工业革命来讲,早一个月把电灯泡拿出来在长的时间跨度上来看是不那么重要的。”
也因此,马化腾“不急”,“我感觉现在有很多公司太急了,感觉是为了提振股价,我们一贯不是这种风格。”
