目前的人工智能,其实还没有什么值得我们恐惧的。
AlphaGo这几日引发了广泛关注,同样引发关注的,出现频率最高的可能就是其背后的“深度学习”的机器学习模型了,也就是这造就了AlphaGo高水平的棋力,让其足以和围棋世界冠军抗衡。
一般认为AlphaGo的核心是两种不同的深度神经网络:“策略网络”(policy network)和 “值网络”(value network)。它们的任务在于合作“挑选”出那些比较有前途的棋步,抛弃明显的差棋,从而将计算量控制在计算机可以完成的范围里。其中,“值网络”负责减少搜索的深度,而“策略网络”负责减少搜索的宽度。
但是“深度学习”却不仅仅是AlphaGo的专属。早在2012年6月,《纽约时报》 披露了Google Brain (微信关注“豆芽情报”查询Google技术布局)项目,就吸引了公众对于“深度学习”的广泛关注。这个项目是由著名的斯坦福大学的机器学习教授Andrew Ng和在大规模计算机系统方面的世界顶尖专家Jeff Dean共同主导,用16000个CPU Core的并行计算平台训练一种称为“深度神经网络”(DNN,Deep Neural Networks)的机器学习模型,在语音识别和图像识别等领域获得了巨大的成功。(内部共有10亿个节点。这一网络自然是不能跟人类的神经网络相提并论的。要知道,人脑中可是有150多亿个神经元,互相连接的节点也就是突触数更是如银河沙数。曾经有人估算过,如果将一个人的大脑中所有神经细胞的轴突和树突依次连接起来,并拉成一根直线,可从地球连到月亮,再从月亮返回地球)。
项目负责人之一Andrew称:“我们没有像通常做的那样自己框定边界,而是直接把海量数据投放到算法中,让数据自己说话,系统会自动从数据中学习。”另外一名负责人Jeff则说:“我们在训练的时候从来不会告诉机器说:‘这是一只猫。’系统其实是自己发明或者领悟了“猫”的概念。”
同年11月,微软Microsoft(微信关注“豆芽情报”查询Microsoft技术布局)在中国天津的一次活动上公开演示了一个全自动的同声传译系统,讲演者用英文演讲,后台的计算机一气呵成自动完成语音识别、英中机器翻译和中文语音合成,效果非常流畅。据报道,后面支撑的关键技术也是DNN,或者深度学习。
2013年1月,在百度(微信关注“豆芽情报”查询百度技术布局)年会上,创始人兼CEO李彦宏高调宣布要成立百度研究院,其中第一个成立的就是“深度学习研究所”(IDL,Institue of Deep Learning)。2015年初,《福布斯》还大幅报道了百度(微信关注“豆芽情报”查询百度技术布局)在语音识别技术上取得重大突破,发明了一种更精准识别语音的新方法。百度首席科学家吴恩达甚至表示,百度在深度学习领域的发展已经超过了Google(微信关注“豆芽情报”查询Google技术布局)和苹果(微信关注“豆芽情报”查询苹果技术布局)。
可以看到,拥有大数据的互联网公司争相投入大量资源研发“深度学习”技术。而其最早为我们所知甚至为我们所用的可能也就是语音识别技术了。Siri掀起的语音交互风暴一直还在蔓延。微软Cortana、Google Now、百度语音助手,大量的独立语音助手面世。而Google恰恰也是该领域的佼佼者,并且已有相当程度的发展。
在智慧芽专利数据库中,搜索Google(微信关注“豆芽情报”查询Google技术布局)公司与“深度学习”相关的专利,共有293件。
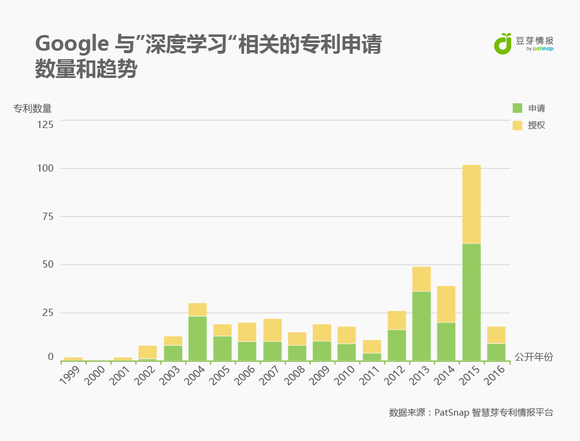
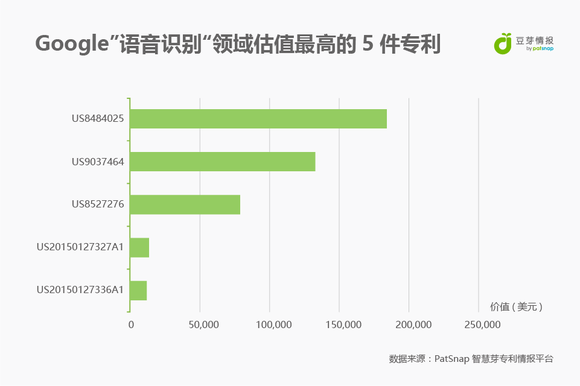
对这些专利进行技术分布分析,其中有一项就是G10L(语音分析与合成;语音识别;音频分析或处理),共有专利15件。图中就是估值最高的5件专利。排名前三的是US8484025,专利标题为映射到操作使用分类器的音频的话语;US9037464,专利标题为计算单词在高维空间中的数字表示;US8527276,专利标题为使用深度神经网络的语音合成(具体专利内容请进入智慧芽专利数据库查询)。
深度学习如何运用到语音识别领域呢?语音识别就是让机器识别和理解语音信号,进而转化为相应的文本或命令。而“深度学习”最大的特点就是其强大的对数据内部结构的表征能力。目前深度学习理论已成功应用于音素识别、大词汇量连续语音识别中,其应用主要集中在利用深度学习方法提取更具表征能力的特征。例如利用瓶颈深度信念网络进行语种特征提取,利用深度信念网络增强 HMM 模型的建模能力等。
总而言之,目前的人工智能,其实还没有什么值得我们恐惧的,没有人类喂给机器的大数据,以及深度学习的机器学习模型,它们连喵星人和汪星人也分不清楚。人工智能未来最大的发展方向还是作为人类的工具,就像它现在所扮演的角色一样——作为语音识别工具,让我们可以在无聊时调戏一下Siri。
