FastSpeech解决了文本语音转换过程中的关键问题——梅尔频谱生成慢。
文|智东西 云鹏
12月12日消息,微软和浙江大学研究人员近日在NeurIPS 2019会议上介绍了文本语音转换模型FastSpeech,该模型可以大幅提升文本语音转换过程中梅尔频谱(mel-spectrogram)生成的速度,从而使得语音生成速度相较于基线提高了38倍。
据研究人员测试表明,FastSpeech的语音生成质量与当下谷歌Transformer模型相当,但有效错误率仅为0%,相较谷歌Transformer模型的基线降低了34%,并且可以在不影响准确性的前提下提升生成语音的语速。以下是对Venturebeat相关报道的原文编译。
目前较为先进的文本语音转换模型,已经可以生成初听起来跟真人几乎一模一样的声音。实际上这些模型支持着像谷歌Assistant、亚马逊Alexa这样的语音助手。
但是这些模型在生成语音过程中有一个共同点,就是都要先根据文本内容生成梅尔频谱——一种声音的数据表现形式,然后根据梅尔频谱,解码器会生成语音。在这个过程中,生成梅尔频谱的速度是非常慢的,而且还会有单词重复和跳过的问题。
为了解决这些问题,微软和浙江大学的研究人员开发了一种机器学习模型FastSpeech,他们在NeurIPS 2019会议上介绍了它,并将其描述为“快速、准确且文本可控的语音转换模型”。
FastSpeech有着独特的体系结构,与其他文本语音转换模型相比有着显著的性能提升:梅尔频谱的生成速度比基线快了270倍,语音生成速度快了38倍。并可以消除跳过单词之类的错误,还可以对速度和单词间的停顿进行细微调整。
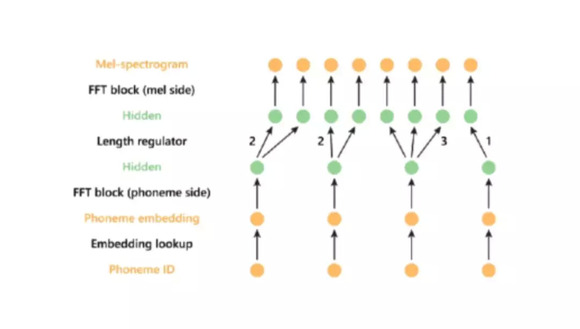
▲FastSpeech的体系结构说明
FastSpeech最重要的结构特点是它拥有一个“长度调节器(Length regulator)”。简单来说,它可以协调梅尔频谱序列与音素序列之间的长度差异。
音素(phoneme)是构成声音的最小单位,由于音素序列的长度通常要小于梅尔频谱序列,因此一个音素就要对应多个梅尔频谱。长度调节器会根据持续时间(duration)来扩展每一个音素的长度(一个预测组件会决定每个音素的持续时间),从而使整个音素序列的长度与梅尔频谱序列长度相匹配。
并且,只需要通过增加或减少与音素对齐的梅尔频谱数量或者音素的持续时间,就可以成比例地调整生成语音的语速。
为了验证FastSpeech的有效性,研究人员使用开源LJ语音数据集对其进行了测试。该数据集包含了13,100个英语音频片段(总时长24小时)和相应的文字记录。他们将语料库随机分为12500个样本进行训练,另外300个样本进行验证,最后剩下的300个样本进行测试。测试期间,他们对语音质量,准确率等指标进行了一系列评估。
测试结果表明,FastSpeech的语音生成质量几乎与谷歌的Tacotron 2文本语音转换模型相同。但是在准确率方面大幅领先于基于Transformer的模型:有效错误率(effective error rate)为0%,而基线为34%。此外,它还能够将生成语音的语速从0.5倍更改为1.5倍,并且不会降低准确性。
此次FastSpeech文本语音转换模型的推出,使得语音生成的速度提高了38倍,并且在准确率方面也将有效错误率降低至0%,虽然测试有一系列的限制条件,但我们可以看出微软和浙江大学研究人员此次推出的模型,仍然对语音生成领域有着重要意义。
AI与人交互的重要方式之一就是语音,人机语音交互已经渗透进现代生活的方方面面,因此语音生成的质量、准确率,以及对生成语音的可控性都是该领域主攻的重点方向。期待此次语音生成技术的突破可以让更多智能语音设备为用户带来更好的体验。
文章来源:Venturebeat
