业务发展与技术升级相辅相成,需要既懂技术又懂业务的产品设计人才作为其中的粘合剂。玖富集团作为综合性互联网金融平台切入人工智能技术研发,与纯技术公司相比具有数据来源和业务理解两方面的先天优势,其成果不仅可以用于提升内部业务效率,技术输出还有更大的想象空间。

指导 | 张扬
调研 | 李喆 刘馥亮 唐靖茹
撰写 | 唐靖茹
日前,2018年政府工作报告指出,要加强新一代人工智能研发应用,在医疗、养老、教育、文化、体育等多领域推进“互联网+”。“人工智能”作为年度绝对热词被写进政府工作报告,可以预期未来工业界和学术界对人工智能的研究将得到更多国家政策支持。
事实上,相比医疗和教育,人工智能在金融领域的应用相对超前,玖富集团就是业界活跃践行者之一。2018年1月,玖富集团与中科院自动化所模式识别国家重点实验室成立“面向金融的智能语音服务联合实验室”,双方将充分结合中科院技术力量和玖富集团业务场景,推进人工智能应用在金融领域加速落地。
玖富集团核心业务包括消费分期、网络借贷、海外证券、大数据征信等,旗下品牌有玖富金融、玖富万卡、悟空理财、玖富证券、火眼征信等,丰富的业务线能够为人工智能技术提供众多落地场景。
玖富人工智能中心属于集团一级部门,除与中科院合作的智能语音外,其着力探索的方向还包括图像识别、语义识别、复杂网络与知识图谱等,在多个业务环节均有应用。提高业务运营效率,减少成本是玖富集团人工智能中心的主要目标,同时也对外输出技术,为公司创收。
玖富人工智能中心总经理赵礼悦表示,数据是AI应用发展的关键,相较于财富管理、保险等细分行业,借贷行业能获得的用户数据更多,因此AI技术渗透最多。具体到业务流程,大致可分为四个环节。
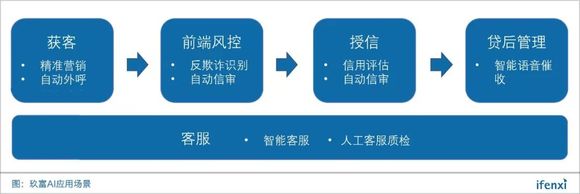
首先是获客环节,主要应用复杂网络算法如标签传播、数据发现等,利用用户之间的网络关系,通过相关性和网络节点定位潜在客户,掌握用户的借贷、理财等方面的行为表现,相应地对潜在用户进行精准营销。进行用户初筛后就可以利用自动外呼系统触达用户,根据其反馈的积极性计算出获客成功的概率,再根据概率从高到低交由电销团队进行维护。
再者是目前应用AI技术最多的风控环节,其中包括前端风控、授信等。反欺诈识别可应用人脸识别、OCR识别、语音识别技术,综合大数据和多轮对话判断申请者意愿和身份真实性。
AI目前最成熟的应用是信用评估,利用大数据和人工智能算法进行特征提取,建立风控模型,验证用户身份,判断个体信用水平、违约风险等。
未来自动信审还可以利用摄像头调用视频,通过视频和多轮对话,嵌入人脸识别、语音识别技术,通过逻辑判断进行信息校验,全自动完成信审工作,起到反欺诈和信用评估功能。
最后是贷后环节,可将语音识别、机器学习等应用在贷后管理中。当用户发生逾期时,使用智能语音与用户沟通,分析判断用户的还款意愿,根据用户给出的还款时间安排人工进行沟通等。
贯穿全程的还有客服环节,运用语义识别、知识图谱等技术,通过大量QA数据训练,实现智能客服,解答客户疑问。除回答问题外,系统还可以实现人工客服质检,实时分析客服人员情绪,监测到有情绪活动时直接进行控制,接管对话。
除与借贷相似的应用场景,其他金融领域的AI应用还有智能推荐。系统以对话机器人的形式从用户处主动收集信息,结合从外部获取的用户标签,与产品标签进行匹配,给出评估和推荐。如保险业务中评估保额,推荐保险产品;证券业务中根据用户关注的个股推荐相关资讯新闻等。主要应用知识图谱中的相关性辅助判断,给出相应的投资建议。
玖富积累的大量真实用户数据对模型训练效果助益颇多,深刻的业务理解能使落地应用更顺畅,未来内部效率提升和对外技术输出成果都值得期待。在赵礼悦看来,有自营金融业务且经过自身业务验证后,再对外输出金融科技能力,相较于无自营业务的金融科技创新公司,优势显著。

近期,爱分析专访玖富集团人工智能事业部总经理赵礼悦,对行业发展趋势和玖富的人工智能技术应用进行了探讨,精选部分内容与读者分享。
赵礼悦,中国科学技术大学本科学位,美国UCF计算机博士学位。曾任爱奇艺大脑深度学习团队负责人。曾担任Elsevier旗下Artificial Intelligence, Pattern Recognition, Big Data Research等人工智能学术期刊的学术编辑,与谷歌研究院,英特尔研究院,CMU等科研机构联合发表人工智能论文十余篇。
金融领域AI对借贷渗透最多,细分场景训练模型更准确
爱分析:AI对金融行业的渗透情况如何?
赵礼悦:渗透还是很多的,但是点比较细碎,有很多非常小的点。
比如说图像方面,像人脸,OCR包括营业执照等一些很细的点的识别。包括语音这块,外呼和智能客服,风控反欺诈等。在玖富内部以及像平安等很多类似的公司,落地蛮多的,特别是在风控反欺诈领域,做的非常多,而且已经非常长时间了,只是怎么做的区别。比如是基于规则,还是基于决策树这种树模型,还是基于深度学习模型,还是基于复杂网络和知识图谱等。
因为底层数据量,包括特征的自动生成,包括模型和反馈系统,其实已经不是简单的某一个机器学习的模型,而是一整套系统里面用到大量技术。
爱分析:金融细分业务包括借贷、财富管理、保险等,AI对哪一项业务的渗透更早更深?
赵礼悦:借贷肯定是渗透最多的,因为借贷的数据相对比较多。现在信用借款比较多,需要用户提供比较多维度的信息,来对用户的信用水平进行建模评估,因此平台会要求授权更多数据。但如果是理财的话,不需要用户提供很多数据,所以理财相对数据少,数据少就意味着做起来会困难很多。AI毕竟是以数据驱动的。
爱分析:不同的细分场景,比如分期中的教育、3C等,是使用通用模型还是针对场景单独开发模型?
赵礼悦:肯定是使用单独的模型。
理论上如果有一个大家都比较喜欢的大一统模型,在任何场景都能用,这是最理想的,但是不可能。针对某一个特定数据集建立的特定模型,在特定场景下表现一定是最好的。
通用模型一定更省事,但是表现一定更差,这就是一个trade off。你是在意模型开发的成本,还是在意模型的表现?如果你在意模型开发的成本,那可以上一个通用模型,但是这样的话表现肯定会差一些,但是节约时间和开发成本。
数据量和业务理解带来发展优势
爱分析:玖富人工智能中心的工作流程是怎样的?
赵礼悦:大概有两方面,一方面是为业务端服务,以业务端需求为导向,这是非常重要的。
另外一方面,也有专门研究纯研究的工作,有点像实验室,但是不叫实验室。比如算法团队,完全是从算法出发,做一些算法的优化和落地工作,然后中间会有一些产品项目,包括工程团队去做。
算法的人可能更关心算法,算法之外肯定是以服务的形式,可能以SDK或者以各种方式去提供算法服务,这是工程人员去做的事情。
其他人员还有产品和运营,包括也对外输出技术,有相应的BD和市场。
爱分析:所以定位不止是提升内部效率?
赵礼悦:这肯定是最主要的目的,另外集团也做一些SaaS服务输出。在跟第三方谈的时候,第三方可能会提到一些想法或者应用,其中有一些涉及AI,我们就会跟SaaS服务的同事一起做技术,这个完全是看第三方的业务需求。
爱分析:相较于纯技术公司做人工智能,玖富的优势是什么?
赵礼悦:业界纯技术公司比较多,玖富的优势就在于有真实用户数据。很多金融公司即使用第三方系统,也要求本地化部署,所以实际上第三方拿不到数据,但是玖富有大量的用户数据,文本量也比较大。
产品上基本思路和架构各家都没太大区别,唯一的区别就在于数据和对业务的理解。比如客服一定要根据业务去设计整体流程,包括话术,一定是对业务了解的人才能做。即使第三方过来,实际上也要拉着业务去做设计,但是内部流程一般是先跟业务聊,聊完后自己写。
真实场景训练才能优化模型,生成特征对人力依赖较大
爱分析:怎样判断一项技术已经成熟,可以运用到实际业务中?
赵礼悦:我们是先出系统再优化模型。
首先业务有需求,先把系统开发出来,然后用相对通用或者简单的模型放进去,把流程跑通。这是相对工程化的思路,上线跑通后才知道哪个模块有缺陷,然后再针对模块中需要优化的,再去做优化。
比如说人脸识别,可能数据库环境下,识别率能到99%,但是一上真实环境,因为用户上传的照片或者拍照的环境各种各样,会产生很大差距,然后再针对性地做一些预处理。很多时候不一定要把图片识别对,其实最难的一点是如何判断这个图片能不能识别对。因为即使识别错了,可以打回去让用户重拍,重拍出来识别率就相当于百分之百。
其实中间有很多小的trick,事实上可以帮助你在模型之外去提高自己的效果。现在AI的产品经理是比较缺的,因为他们既懂AI又能懂产品设计,可以利用产品设计优化去规避一些AI的弱点,这才是最厉害的,也是未来AI能够真正落地的一个关键能力。AI的算法可能永远达不到百分之百,在这种情况下,怎样去设计产品,让AI发挥最大效果才最重要。
爱分析:开发人工智能应用对人力的依赖重吗?
赵礼悦:Training的过程中确实重,包括在生成特征的时候,是最典型的。
生成特征对人力依赖最大,因为生成特征一定是业务相关的,比如说这一套系统,用户收集的数据,可能原始数据有几百位。第一步是特征提取,第二步建模,然后第三步输出,然后就是off-line和on-line。
这套流程其实风控反欺诈可以用,推荐系统也可以用,但是区别在哪?就是从数据转化为特征这一层的过程中,要提什么样的特征,一定是业务相关。比如说要做推荐,那肯定做跟推荐相关的一些特征,要做风控反欺诈,肯定是跟风控反欺诈相关的一些特征。这些都是跟业务强相关的,一定要有业务人员指导。
跟业务聊得多的话,大概能体会到有哪些可能是比较有用的。有些特征组合可能是完全没有道理的,但就是事实,就是好用,而且加这个特征以后就是能提高一两个百分点。
根据应用需求选择算法,平衡模型与特征
爱分析:各种不同的机器学习算法有哪些评价维度?
赵礼悦:工业界和学术界有一个很大的区别,学术界在意的主要正确率,而工业界在意的远远比这个多得多。
首先是算法稳定性,算法对脏数据的承受能力。比如为什么现在有这么多深度学习模型,但大家还是愿意用LR逻辑回归?为什么用GBDT,XGBoost,Random forest这种算法?
LR的好处就是可解释性比较强。GBDT和Random forest的好处有几点,一点是对缺失值相对不敏感,因为有很多标准方法去补充,而缺失值在风控反欺诈里面是非常常见的一个问题。另外一点就是它的可解释性也还OK。比如说随机森林这种算法,它可以产生特征重要性排序,就是如果硬要解释,也可以解释一下,这种相对比较好。
深度学习可能会把正确率提高一两个百分点,这在学术界可以发很牛的paper,因为一两个百分点已经蛮高了。但是在工业界可能关注的很多不是这个。在这种情况下,要不要用,在哪些场合下用,面临很多问题,比如说监管的问题,数据的问题。
不管是传统的也好,还是新的算法也好,关注的点有稳定性,对脏数据的可扩展性,包括提到的,比如特征维度是几千万维的时候,LR可以跑起来,因为LR做分布式训练相对比较简单,但是如果用GBDT或者深度学习的话,相对来说就难一些。深度学习这么多维度的还没有试过,但是像GBDT这种训练成本就非常高,数据量都很大,参数又那么多,需要不停地调。
爱分析:所以现在并没有明确的孰优孰劣?
赵礼悦:绝对是case by case的,主要看你在意的指标是什么。这是一个 trade off,你是相信feature 给你带来的增益更大,还是相信模型给你带来的增益更大,然后再去决定是用什么方法。
